This project is my first major foray into Lambda and how it operates as I wanted to
learn more about Python and being able to interact and modify resources based on set
triggers.
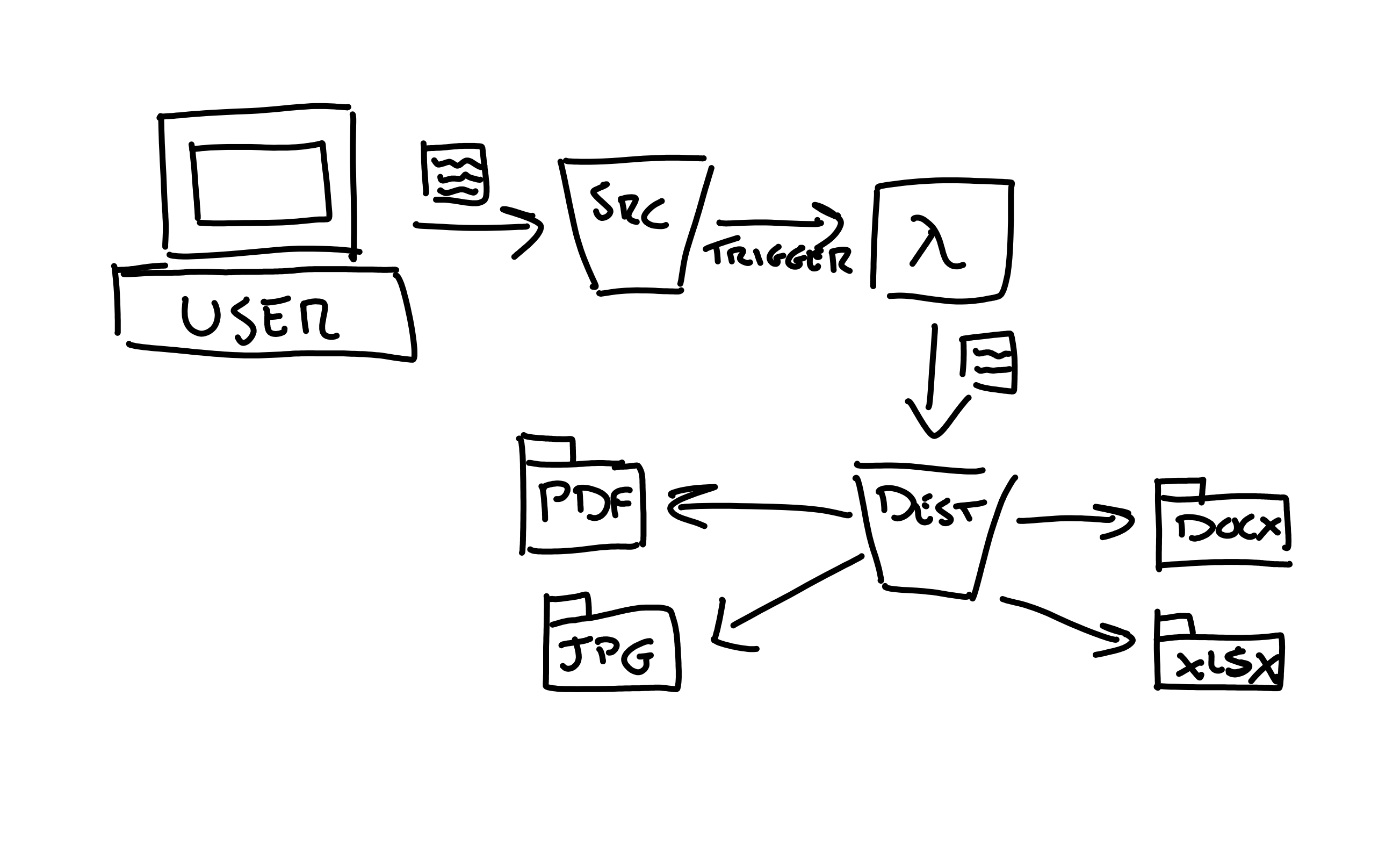
I set out this project with a common use case: To be able to automate the management of
S3 objects by being able to automatically place them into the necessary folders and then,
depending on the object type, edit the object contents accordingly.
As this is a beginner project, I built the function to automatically sort the objects
by way of their file type, i.e. PDF's, JPG's and Word documents. I chose this because
it was easy information to take from the file as I had multiple ways to identify this information
using fairly common methods.
In order to make the sort work effectively, I created two buckets: a source bucket and a
destination bucket. The source bucket, as the name implies, purely exists for the user to
upload their objects. This then triggers the Lambda function which parses the information,
identifies the file type and then copies it into the destination bucket with the file type
added in to create a mock folder structure.
Automating object management on S3 with Lambda
The Goal
The Benefits
Whilst my initial use case is relatively basic, it is very flexible. By splitting the objects
into the individual file types then allows for greater control when setting object tags and
even lifecycle policies. For example you might want to move word documents into the Glacier
class after 3 months, but for PDF's it might be after 6 months to a year. By then giving each file type
a consistent prefix it is then much easier to manage your lifecycle policies set on a per prefix
basis.
This code can also be a good base to expand further, for example building out the folders based on the month and year uploaded, the tags attached to the object or even the size of the object. This allows for some fantastic opportunities to keep your object management consistent and then progress from there into further automation potentials (i.e. automatically resizing images or sending SNS topics based on spreadsheets that exceed a certain size).
We can also use this process build out restrictions on the sorts of objects that can be uploaded to the bucket, for example if you have a PDF document that is missing a certain tag or exceeds a certain size it can return an error and then either delete the source document or move to a third bucket.
There are a number of different ways that you can manage your S3 usage, and Lambda triggers therefore are a fantastic way of automating this process.
This code can also be a good base to expand further, for example building out the folders based on the month and year uploaded, the tags attached to the object or even the size of the object. This allows for some fantastic opportunities to keep your object management consistent and then progress from there into further automation potentials (i.e. automatically resizing images or sending SNS topics based on spreadsheets that exceed a certain size).
We can also use this process build out restrictions on the sorts of objects that can be uploaded to the bucket, for example if you have a PDF document that is missing a certain tag or exceeds a certain size it can return an error and then either delete the source document or move to a third bucket.
There are a number of different ways that you can manage your S3 usage, and Lambda triggers therefore are a fantastic way of automating this process.
Learning about Boto3
As a self-confessed novice at Python the most I've been able to experience previously has been
working with lists and basic for loops, so I was familiar with the syntax but not much beyond that.
Seeing the demand that Python and Node.JS has on the market, having more real world experience with these languages felt like a no brainer to me, especially if it leads me to design and build better architectures with automation at the very core.
Due to my lack of experience, this is the first time I've used Boto3, or even the import functionality of Python in general. Getting to grips was fairly easy after a Python refresher (thanks freecodecamp!) and as I started to read through real world examples I was able to understand fairly quickly what was happening with each line of code.
One thing I did struggle with was where to use
During this exercise I kept the Boto3 guide close to hand however I did find this initially overwhelming due to the sheer amount of information which probably expects a higher level of understanding of the basics of the SDK and Python in general. I will definitely need to focus on this further as my experience increases.
Seeing the demand that Python and Node.JS has on the market, having more real world experience with these languages felt like a no brainer to me, especially if it leads me to design and build better architectures with automation at the very core.
Due to my lack of experience, this is the first time I've used Boto3, or even the import functionality of Python in general. Getting to grips was fairly easy after a Python refresher (thanks freecodecamp!) and as I started to read through real world examples I was able to understand fairly quickly what was happening with each line of code.
One thing I did struggle with was where to use
boto3.client('s3') vs boto3.resource('s3')
as the resources I found online did tend to differ depending on the context. In the end I used boto3.client
as it felt easier to get to grips with the commands available such as get_object as it
ties in better in my head with using the right IAM and Bucket Policies, so it was easier to visualise
what actions should be included in the policies.
During this exercise I kept the Boto3 guide close to hand however I did find this initially overwhelming due to the sheer amount of information which probably expects a higher level of understanding of the basics of the SDK and Python in general. I will definitely need to focus on this further as my experience increases.
The Code
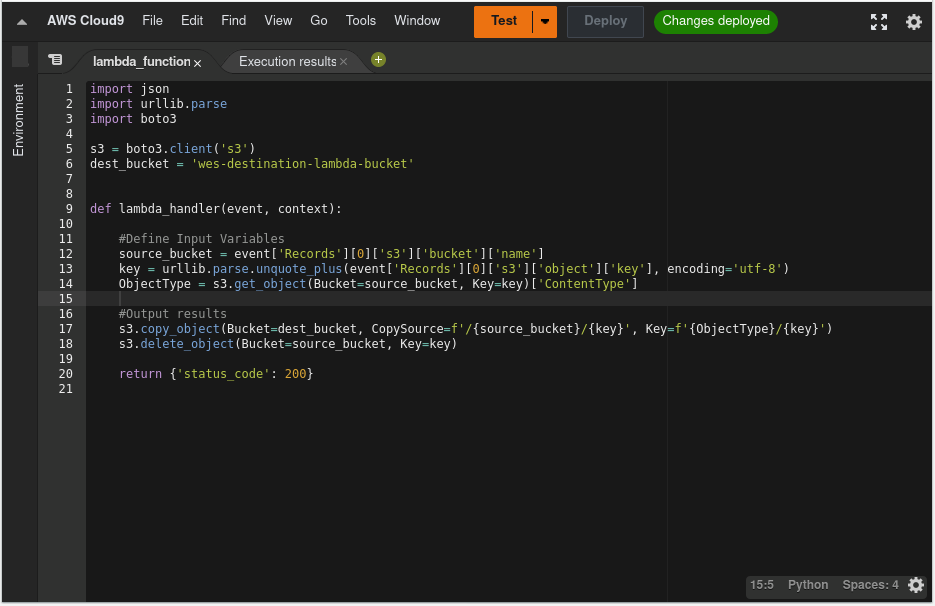
In my code I have split it into a few sections: the global variables, the object variables, and then the output.
My global variables I have kept very basic, simply defining
My object variables is calling and storing the bucket, object key as well as the object type that are generated from the trigger. Whilst I could hard code my source bucket as well, I decided to import this from the example that I used from the AWS webpage so that I'm not limited if I decided to add more source buckets at a later date.
The object key uses
I then pulled through the object type using the
My global variables I have kept very basic, simply defining
s3 = boto3.client('s3') as a short hand
and then calling the destination bucket. This could be improved using Secrets Manager at a later date again to automate
any changes that need to be made at a later date as well as improving security.
My object variables is calling and storing the bucket, object key as well as the object type that are generated from the trigger. Whilst I could hard code my source bucket as well, I decided to import this from the example that I used from the AWS webpage so that I'm not limited if I decided to add more source buckets at a later date.
The object key uses
urllib.parse to pull from the nearly 40 lines of JSON that is sent in the trigger
the name of the object, this could also be done using the List-Objects-v2 resource however at the time of
creation as urllib.parse was already included I decided to keep that as is although the code should be very
similar.
I then pulled through the object type using the
get_object command, which pulls through the standard
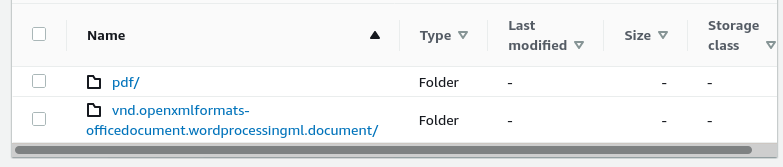
information that is gathered by AWS. This does make for some interesting folder names when, for example uploading a
word document creates the folder as "vnd.openxmlformats-officedocument.wordprocessingml.document", as opposed to "docx".
When researching for this project, the first thing I found out when it comes to the Python SDK is that there is no "move"
function, instead you need to apply a copy function and then a delete function to remove the original document. This format
also applies to renaming documents. This works in my favour as the copy function also allows us to do the necessary renaming
necessary for the folder structure to work properly.
Lastly, to ensure that the function exits correctly, I included a
Lastly, to ensure that the function exits correctly, I included a
return {'status_code': 200} to show a correct
execution of the function.
Working with Folders
One of my main concerns with this project initially would be the creation of the folders when uploading a new object,
as I wasn't sure if you had to create the folder first before you're able to place the object. Doing some testing with
a test bucket and some basic use of the copy command showed me that I in fact didn't need to worry about creating the folders,
and as long as the folder naming is consistent, the files will follow suit. I was aware that this is because S3 doesn't have
a folder structure per se, but instead builds the folder functionality into the name of the object, and then uses that
to simulate a standard folder structure.
As mentioned above because we're pulling through the object type from the metadata it can come back with some wacky and wonderful object types like the aforementioned word document. I could counter this by retrieving the object type based on the file extension at the end of the object, for example "testspreadsheet.xlsx" would have the file extension and therefore folder .xlsx. This could be done by using the
This would make more sense for those who understand their file types better, but does mean that similar documents will be separated, such as .XLSX and .XLSM, whereas as it stands currently there is more chance of similar items being captured within the same folder structure, so the use case depends on the specific items that are being stored as to which you should use.
As mentioned above because we're pulling through the object type from the metadata it can come back with some wacky and wonderful object types like the aforementioned word document. I could counter this by retrieving the object type based on the file extension at the end of the object, for example "testspreadsheet.xlsx" would have the file extension and therefore folder .xlsx. This could be done by using the
.split() resource in Python to store everything after the last full stop. The upside to this
is that for those items who then do not have a file extension, we can build in their own folder called "Uncategorized".
This would make more sense for those who understand their file types better, but does mean that similar documents will be separated, such as .XLSX and .XLSM, whereas as it stands currently there is more chance of similar items being captured within the same folder structure, so the use case depends on the specific items that are being stored as to which you should use.
Execution Roles and Bucket Policies
In order to maintain least privilege security on this project I set the necessary policies
to ensure that the Lambda function has access to purely what it needs and the S3 buckets
are allowing what is necessary for the function to run.
With the Lambda function I added to the standard role the abillity to list the objects on the source bucket and allowing Put operations on the destination bucket and Delete operations on the source bucket. These policies have a direct correlation with the code that is run on the function to ensure that I am not providing more access than is strictly necessary.
With the Lambda function I added to the standard role the abillity to list the objects on the source bucket and allowing Put operations on the destination bucket and Delete operations on the source bucket. These policies have a direct correlation with the code that is run on the function to ensure that I am not providing more access than is strictly necessary.
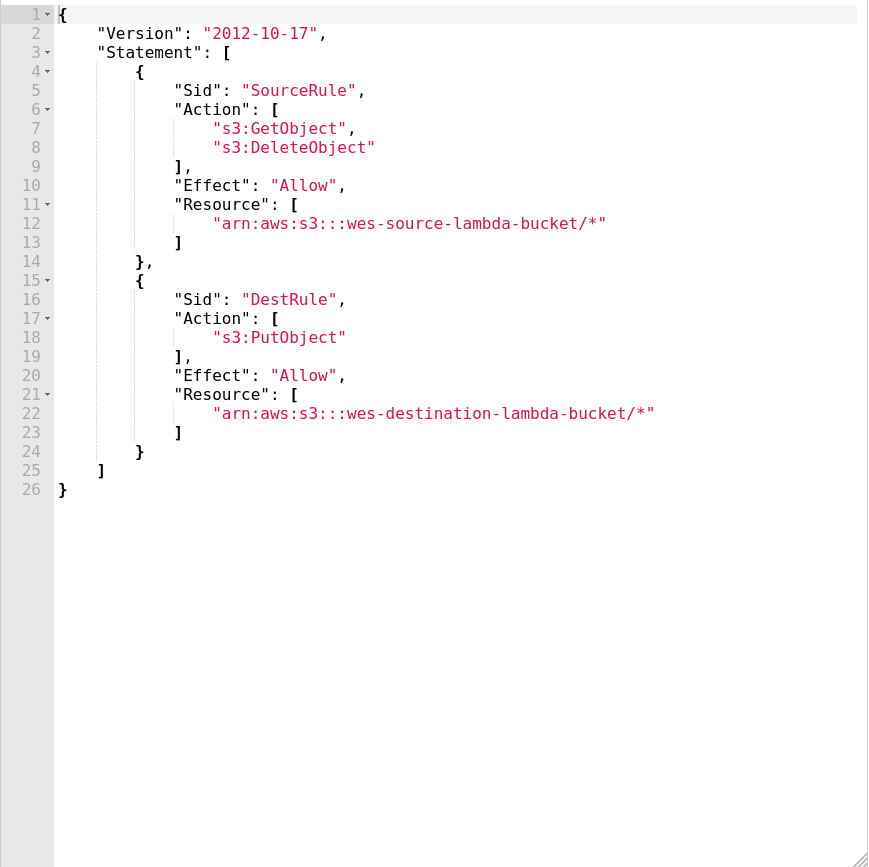
For the S3 bucket policies I reflected the policies that existed on the Lambda role to the respective bucket,
so the source bucket allowed GetObject and DeleteObject and the destination bucket allowed PutObject.
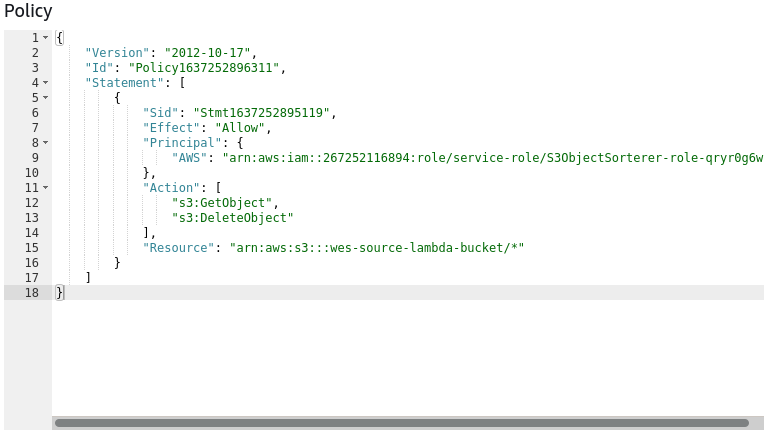
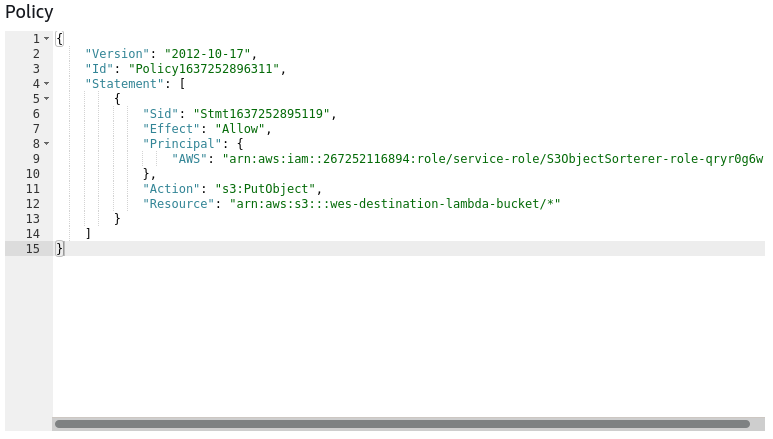
This was my first time really getting to grips with configuring the policies using JSON and,
whilst it was not as easy to configure as YAML, it was not as difficult as I thought once I understood
how the syntax works.
The good thing about configuring the policies in this way is that you can then completely lock down the destination bucket away from the source bucket and provide a more consistent experience for users.
The good thing about configuring the policies in this way is that you can then completely lock down the destination bucket away from the source bucket and provide a more consistent experience for users.
The lambda_handler
as I started this project, my first instinct was to remove the template function that
calls "Hello World!" and start from scratch in order to aid my learning and this is where
I ran into my first issue, by doing so when it came round to creating my function I started off
with my own name and calling my own inputs as the initial vision was fairly different to how it
resulted.
As I then started to run through my code I would then run into errors stating that there is an issue because the
As I was researching, I did note that I could create multiple named functions and then call them within the lambda_handler function and that will work just fine, so that is a good point to bare in mind in future.
As I then started to run through my code I would then run into errors stating that there is an issue because the
lambda_handler didn't exist. In my naivety I believed this was a configuration error
and that I was missing something in the settings based on my research online. It wasn't until I
opened up another Lambda function that I was able to spot that the function itself was called lambda_handler,
after amending the code accordingly to call the function lambda_handler and formatting it
correctly the code then ran correctly.
As I was researching, I did note that I could create multiple named functions and then call them within the lambda_handler function and that will work just fine, so that is a good point to bare in mind in future.
Cost
The great thing about using Lambda for these micro-operations is the fact that it uses so little
resources that all of my testing was able to operate under the free tier, just paying for the S3 storage space.
This has inspired confidence in myself to play around with Lambda more as it is so cost effective and so powerful
at the same time that it is a must use service.
Takeaways
This project has given myself the most amount of learning out of all the projects I've completed so far,
primarily because I had so many mini lessons that added up to a fantastic first experience with Python
and my first real taster of Lambda in anger. This has inspired new confidence in me to explore Python further
and use Lambda to really push my architectures further.